前一篇中,介紹Pandas要如何處理數據有缺失值的情況,才能做正確的數值、統計運算, 今天要來介紹如何做分層索引(Hierarchical Indexing),
在資料運算中,需要確認資料格式外,更加需要了解目前區要的資料項目為何者,因此本節介紹,在pandas如何做資料索引。
ndex = [('California', 2000), ('California', 2010),
('New York', 2000), ('New York', 2010),
('Taiwan', 2000), ('Taiwan', 2010)]
populations = [300000000, 3545788006,
142467897, 1937424222,
20851220, 22222261]
pop = pd.Series(populations, index=index)
pop

pop[('California', 2010):('Taiwan', 2000)]
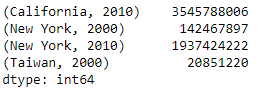
1.Pandas MultiIndex
index = pd.MultiIndex.from_tuples(index)
index
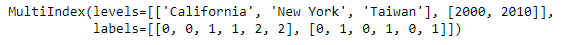
pop = pop.reindex(index)
pop

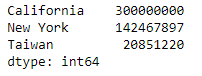
pop[:, 2000]
2.將Pandas MultiIndex產生的類別,作為資料的另外一個維度
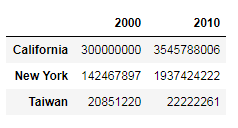
pop_df = pop.unstack()
pop_df
pop_df.stack()

3.Methods of MultiIndex Creation
pd.MultiIndex.from_arrays([['a', 'a', 'b', 'b'], [1, 2, 1, 2]])
pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('b', 1), ('b', 2)])
pd.MultiIndex.from_product([['a', 'b'], [1, 2]])
皆可以產生下圖的資料格式: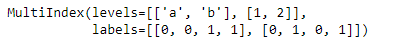
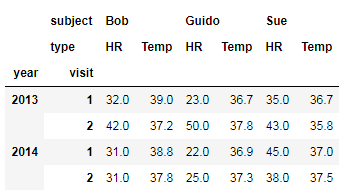
4.MultiIndex for columns
# 建立行列分層索引
index = pd.MultiIndex.from_product([[2013, 2014], [1, 2]],
names=['year', 'visit'])
columns = pd.MultiIndex.from_product([['Bob', 'Guido', 'Sue'], ['HR', 'Temp']],
names=['subject', 'type'])
# 建立數據
data = np.round(np.random.randn(4, 6), 1)
data[:, ::2] *= 10
data += 37
# 建立 DataFrame
health_data = pd.DataFrame(data, index=index, columns=columns)
health_data
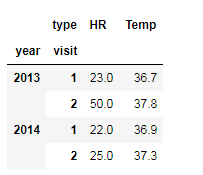
health_data['Guido']
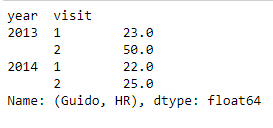
health_data['Guido', 'HR']
health_data.iloc[:2, :2]


